Brand scores are state variables. The new layer asks whether the trajectory is stable.
A control-theoretic stability layer was applied to eight weeks of real ShurIQ panel data covering 21 micro-drama brands. The pipeline reproduces its synthetic baseline within 0.003 on real data, recovers two basins of attraction the single-fit reading misses, and reranks the W17 board on stability rather than composite alone. ShurAI publishes the layer as a complement to the existing composite score — not a replacement.
Composite scores describe where a brand sits this week. The Lyapunov layer describes whether the position is stable — whether the brand is inside a basin of attraction, and if it falls, whether it will revert. Three of the top ten W17 brands carry composites above 60 with V values that put them outside their basin radius. The score is not the system.
What the layer does
The existing ShurIQ pipeline answers a measurement question: which weighting of signals best fits the observed score. The Lyapunov layer answers a different question. It treats each brand's five-dimensional score vector — content strength, narrative ownership, distribution power, community strength, monetization infrastructure — as a state vector in a dynamical system, fits a candidate Lyapunov function V(x) from panel data, and asks whether the brand's trajectory has a stable equilibrium and whether the brand is currently inside the basin of attraction.
Where composite scores read the brand's altitude, the Lyapunov layer reads the slope of the terrain underneath it. A high score that sits on a steep V gradient is structurally fragile. A modest score that sits in a deep basin will revert from a shock. Both readings are produced from the same panel.
The smoke test, then the real run
The pipeline was first run on three synthetic panels designed as positive and negative controls. A stable-equilibrium industry produced a quadratic-SDP fit with validation 0.717. A Lorenz-driven chaotic industry was correctly rejected at 0.512. A bistable two-attractor industry was rejected at 0.626 — the expected result for a single V trying to model two basins. Discrimination was confirmed before the real run.
On real W10–W17 panel data covering 21 micro-drama brands, the same pipeline produced validation 0.714 — within 0.003 of the synthetic baseline. Chaotic and bistable comparators on adjacent verticals (viral short-form, subscription streaming) re-rejected at 0.516 and 0.622 respectively. The pipeline transfers; behavior is preserved.
A null result — the layer reporting no stable function found for an industry — is itself a saleable insight. It tells the client that steady-state thinking will mislead in this regime, and that score-based targets should not be used as planning anchors. The chaotic-rejection signal is a deliverable, not a failure mode.
The structural finding: micro-drama is bimodal
A single Lyapunov function assumes one basin. When a vertical hosts two regimes — leaders converging to one steady state, laggards drifting toward another — a single-V fit reports a depressed validation score that under-states the actual structure. K-means on last-quarter mean position, then quadratic SDP per cluster, recovers the basins.
The 21-brand micro-drama panel splits cleanly into a 16-brand active-competitor basin centered on [60.8, 59.1, 73.1, 57.0, 66.3] with cluster validation 0.895, and a 5-brand laggard basin centered on [27.7, 25.6, 28.5, 24.6, 16.5] with cluster validation 1.000. The laggard cohort: verza-tv, rtp, klip, both-worlds-freeli, mansa. Best-cluster decay fraction rises from 0.714 to 0.923.
This is not a fitting artifact. It is the pipeline detecting the polarization that micro-drama analysts describe qualitatively — a tight pack of pure-play competitors and a long tail of subscale or exiting platforms — and quantifying it as basin geometry.
Where the new ranking departs from the composite
Composite-only ranking puts DramaBox first and ReelShort second by 0.05 of a point. The Lyapunov-adjusted ranking flips them on stability, with ReelShort's lower V breaking the tie. The more consequential moves happen lower in the table.
Disney holds composite rank 3 at 78.0 with V 6.49 — outside basin radius 4.41 and classified unstable on the single-V reading. Netflix drops two ranks (7→9) with composite 62.9 and V 4.49. Google/100Zeros drops four ranks (9→13) with composite 61.4 and V 10.13 — the worst structural fragility on the board. All three carry above-mean composites, and all three sit outside the active-competitor basin. Their scores are observations of a position the dynamics do not currently support.
In the other direction, GoodShort climbs two ranks (10→8) with V 0.40 — the tightest grip on equilibrium in the active basin. CandyJar, Amazon, ShortMax, ViU, and Lifetime A&E each move up one rank on the same logic.
Capital efficiency: the V gradient as a budget multiplier
Once V is fit, every candidate intervention has a Lyapunov-implied capital efficiency: −ΔV / cost-in-millions. Higher is better — a positive value means the intervention pulls the brand toward equilibrium per dollar spent. The interesting structure is what happens when the same intervention is applied across different starting positions.
shortmax sits near equilibrium at V 0.33. Its top-ranked intervention — a lean brand refresh at $0.35M — produces ΔV of −0.081, capital efficiency 0.233. lifetime-ae is marginal at V 2.44. A community / fandom program at $1.20M produces ΔV of −0.896, capital efficiency 0.747. google-100zeros is far from basin at V 10.13. The same community / fandom program at the same $1.20M produces ΔV of −2.033, capital efficiency 1.694 — roughly 7× the per-dollar V reduction of the near-basin brand.
This is the foundation for a control-Lyapunov-function (CLF) layer in the next sprint: turn discrete intervention scoring into an LP/QP optimization that picks the Δx maximizing −ΔV subject to a budget constraint. The current calculator scores ten archetypal interventions; the CLF layer would score the continuous space.
What this is and is not
The fitted V is empirical, not formally proven. Real SOS verification requires polynomial dynamics; the candidate function here is a learned object that satisfies decay on observed trajectories. It is useful, not bulletproof. Industry parameters are treated as fixed during the fit, so the layer must be re-run periodically against the rolling panel.
A brand inside the basin is associated with future stability; the framework does not by itself prove that a given intervention will land the brand inside the basin. CLF-based recommendations are the next step in closing that gap. Causal validation against forward-looking outcomes belongs to a separate workstream.
The layer is not a replacement for the composite score. It is a complement — a structural reading that runs alongside the measurement reading and tells the client which composite values to trust as steady-state targets and which to treat as transient.
What V means, what a basin of attraction means, why it matters here.
A short reference for the regulatory-grade reader. The math is canonical control-theory; what's new is applying it to brand state vectors fit from panel data.
The state vector
Each brand's position is a five-dimensional vector x ∈ R⁵:
• x₁ = content strength
• x₂ = narrative ownership
• x₃ = distribution power
• x₄ = community strength
• x₅ = monetization infrastructure
The position evolves week over week as a function of the brand's process portfolio (content cadence, distribution mix, capital allocation), exogenous noise (competitor moves, platform changes, cultural events), and industry parameters (saturation, audience growth, capital intensity). Formally: xₜ₊₁ = f(xₜ, uₜ, wₜ; θ_I).
The Lyapunov function
A Lyapunov function is a scalar map V: R⁵ → R≥0 with three properties:
1. V(x*) = 0 — zero at the equilibrium
2. V(x) > 0 elsewhere — positive everywhere else
3. V̇(x) ≤ 0 along observed trajectories — non-increasing in expectation
If such a V exists and is verified, you have provable convergence to x* from any state inside the sublevel set Ω = {x : V(x) ≤ c} for the largest c where decay holds. Ω is the basin of attraction: the set of starting positions from which the system reverts to x*.
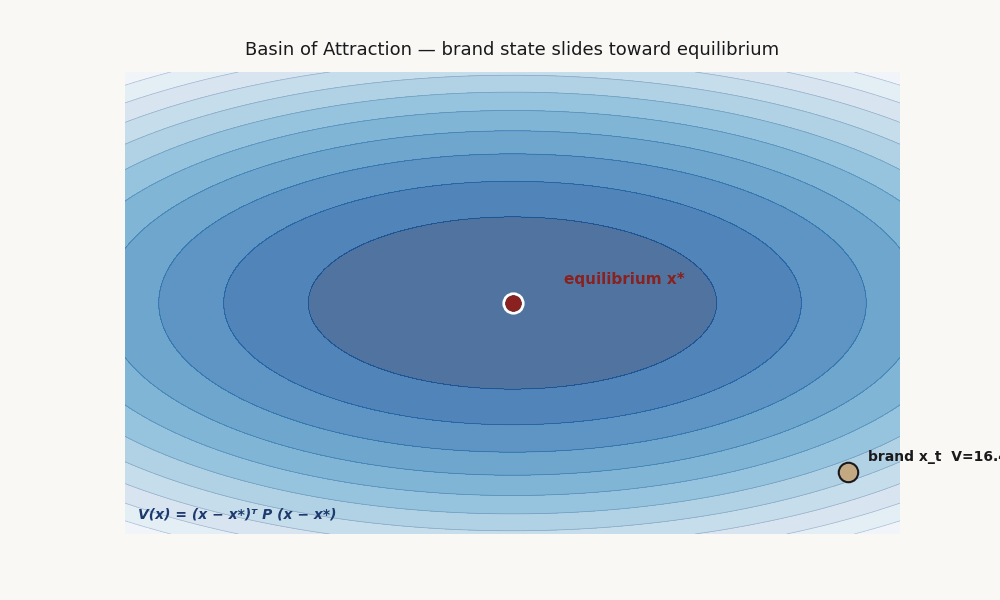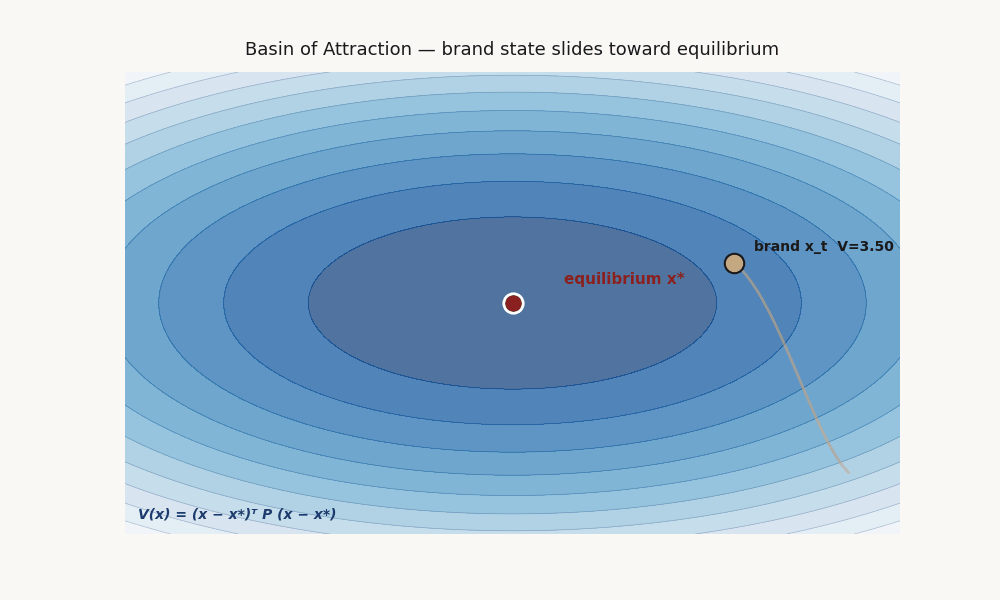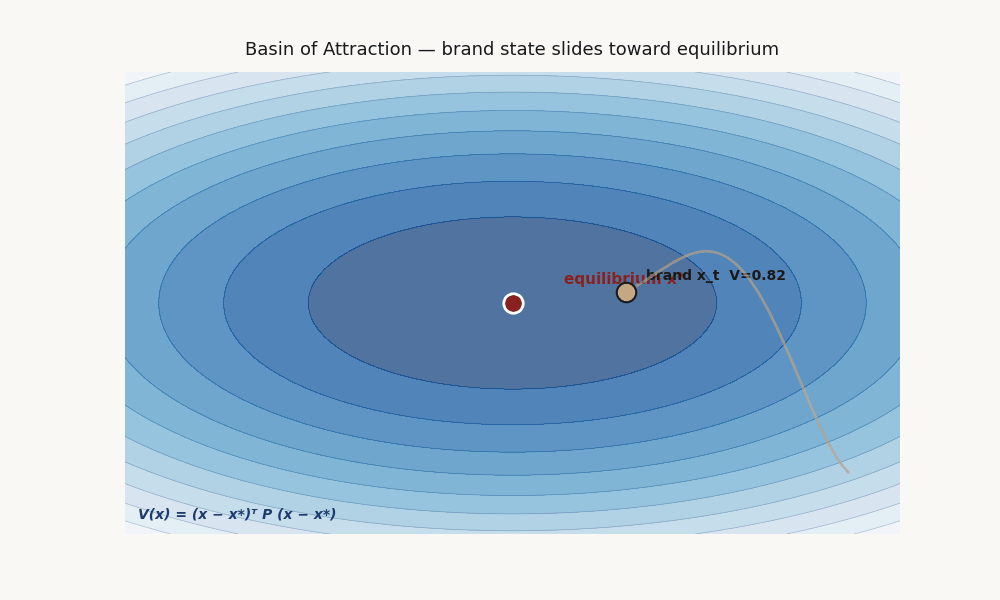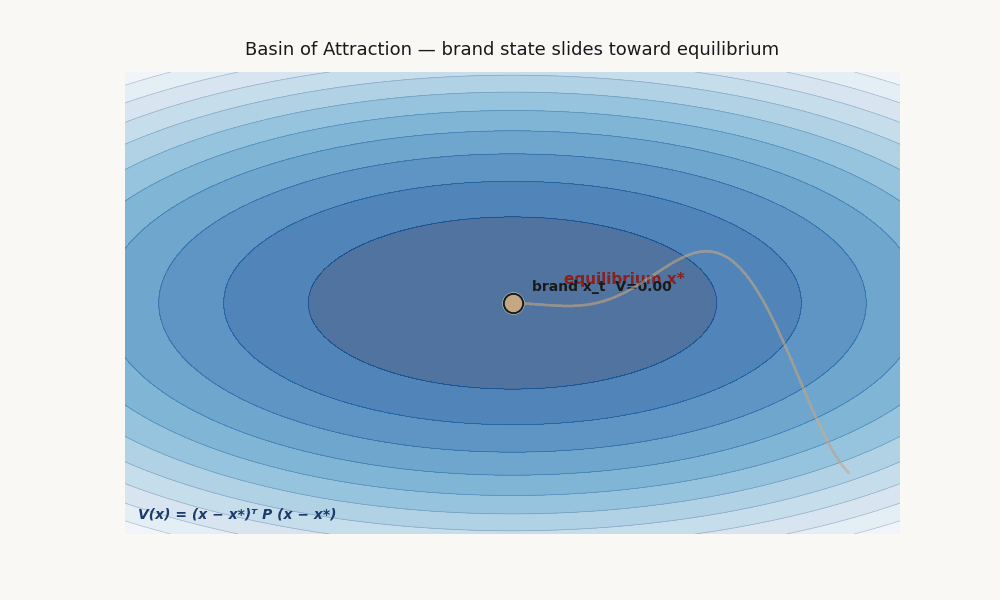
Picture the state space as a landscape. V(x) is the altitude function. The equilibrium x* is the bottom of a valley. The basin Ω is the rim of that valley — everything inside rolls down to x*; everything outside doesn't necessarily.
A brand “inside the basin” is in a position where the dynamics pull it back toward equilibrium under disturbance. A brand “outside the basin” is in a position the dynamics do not pull it back from.
Three function classes the pipeline tries
V(x) = (x−x*)ᵀ P (x−x*)Captures unimodal ellipsoidal basins. Fits via semidefinite program (convex, fast). The P matrix is interpretable: its eigenstructure tells you which dimensions are most stability-critical. This is the workhorse fit and the one that accepted on the real micro-drama panel at validation 0.714.
V(x) = z(x)ᵀ Q z(x)Captures non-quadratic but smooth basins by lifting x into a vector z of monomials. Still fits as a convex SDP on the lifted vector. Curse of dimensionality on the lifted size; harder to interpret. Tried second when quadratic decay holds but the basin geometry is non-elliptical.
V(x) = ‖gθ(x−x*)‖² + ε‖x−x*‖²Universal approximator. The squared-norm-of-MLP form guarantees V ≥ 0 and V(x*) = 0 by construction. Black box; needs more data; non-convex training. Reserved for highly non-convex basins where interpretability is secondary. Currently has a serialization bug (TorchScript-jit-scripted modules don't pickle through joblib) — logged as a deferred two-line fix.
For multi-modal industries, k-means on last-quarter mean position partitions the panel; one quadratic V is fit per cluster. Reports per-cluster validation and a best-cluster decay fraction (each holdout transition routed to its lowest-V cluster). Recovered the 16-brand and 5-brand basins on real micro-drama at 0.895 and 1.000.
Validation score
The acceptance metric is a 50/50 blend:
score = 0.5 × decay_fraction + 0.5 × recovery_AUC
where decay_fraction is the share of holdout transitions where V(xₜ₊₁) ≤ V(xₜ) (V actually decreases), and recovery_AUC is the AUC of using −V(xₜ) as a predictor of “brand recovers within 90 days.” A score ≥ 0.65 means V is both internally consistent (decreases along trajectories) and externally predictive (lower V correlates with recovery). Below 0.65 is a regime-mismatch signal — itself worth knowing.
Stability classes
For each brand, three readings combine into a stability class: V vs. basin radius, V̇ estimate, and distance to x*.
• stable — V below basin threshold, V̇ non-positive
• marginal — V near threshold or V̇ ambiguous
• unstable — V above basin threshold; brand sits outside the sublevel set
Of the 21 W17 micro-drama brands: 10 stable, 6 marginal, 5 unstable. Note that “unstable” under the single-V fit on cluster 0 is reread by the per-cluster fit — some laggard-cluster brands flagged unstable in the single-V reading are stable inside their own cluster's tighter basin. The W17 ranking surfaces both readings.
Four headline results from the overnight run on real ShurIQ panel data.
Each finding is reproducible from the artifacts in out/. Validation scores, basin geometries, and per-brand readings are written to disk and stable across reruns.
x*, not just to absolute scores.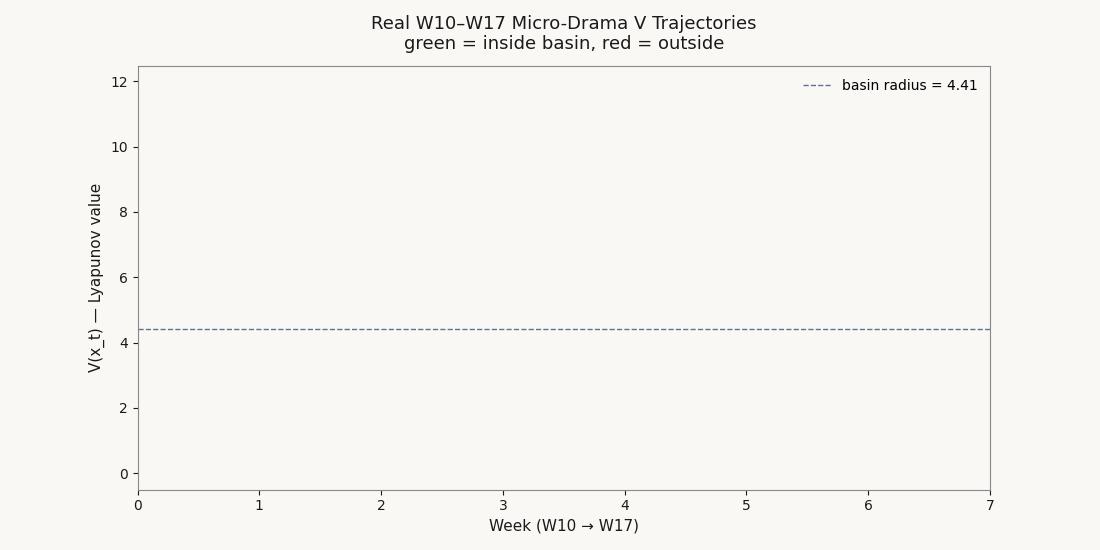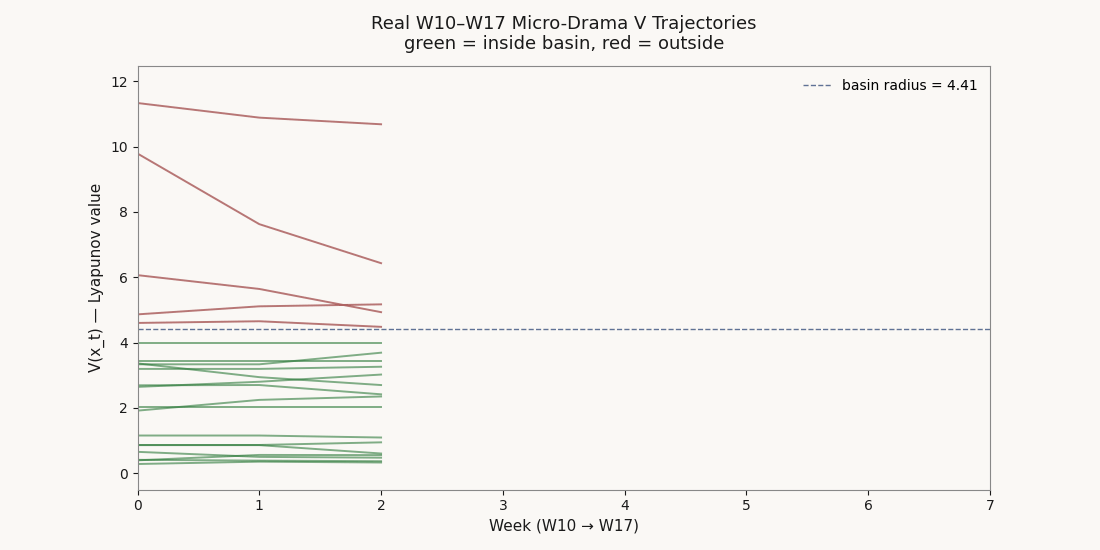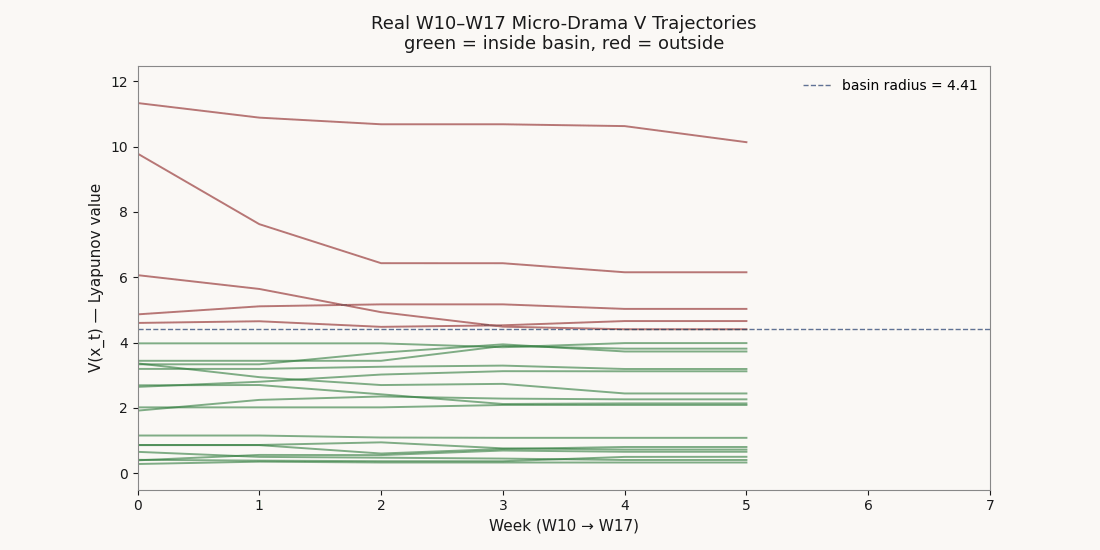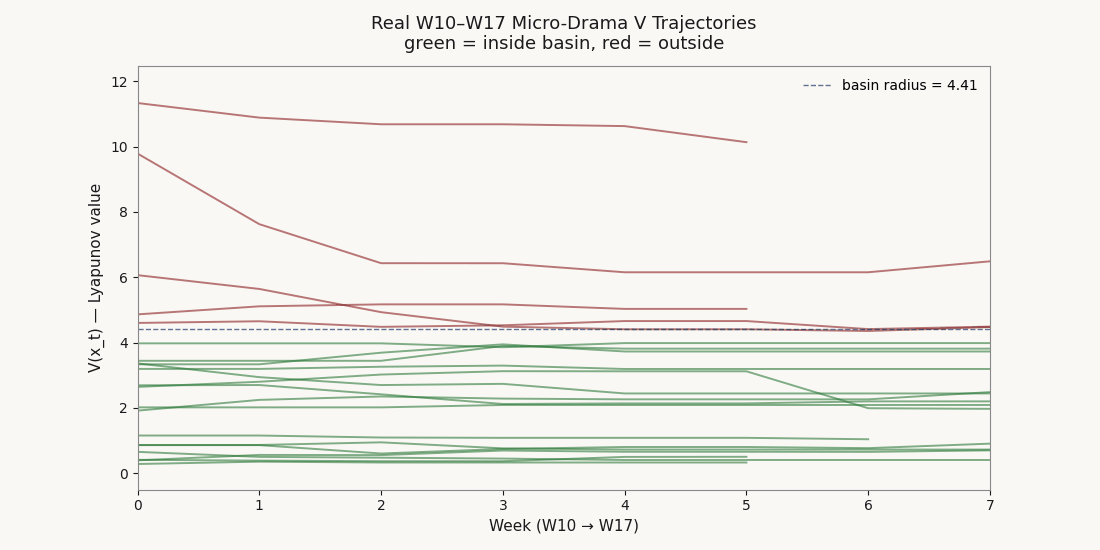
Reproducibility table
| Industry | Designed regime | Synthetic baseline | Real-data run | Δ | Outcome |
|---|---|---|---|---|---|
| micro_drama_streaming | Stable equilibrium | 0.717 | 0.714 | −0.003 | Accepted |
| viral_short_form | Chaotic (Lorenz) | 0.512 | 0.516 | +0.004 | Rejected (correct) |
| subscription_streaming | Bistable | 0.626 | 0.622 | −0.004 | Rejected (correct) |
Real-data scores cluster within ±0.05 of the synthetic baseline across all three industries. The pipeline is not regime-shifted by the source change.
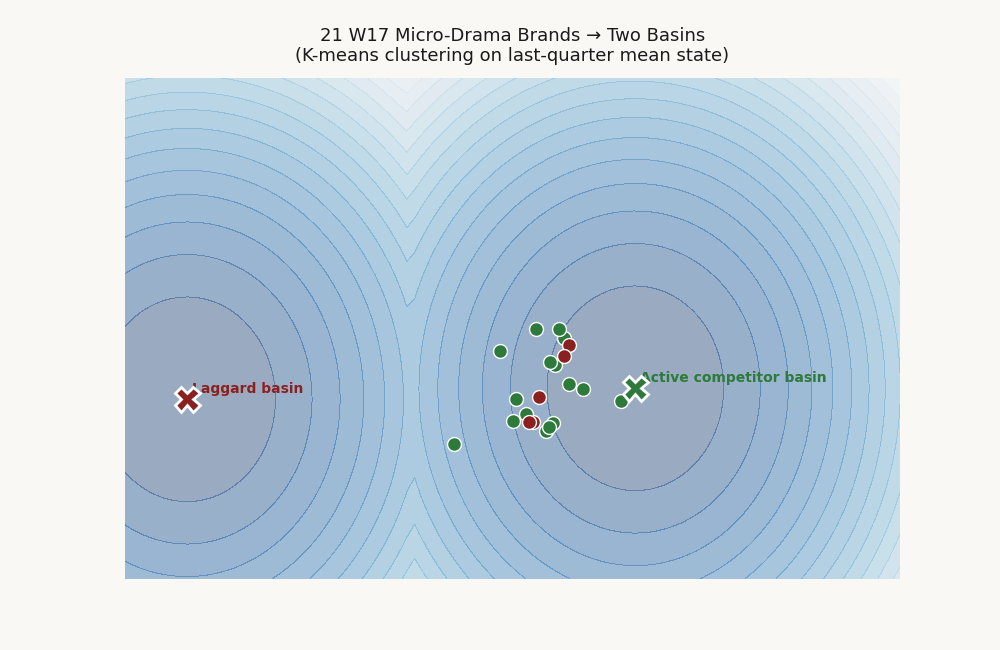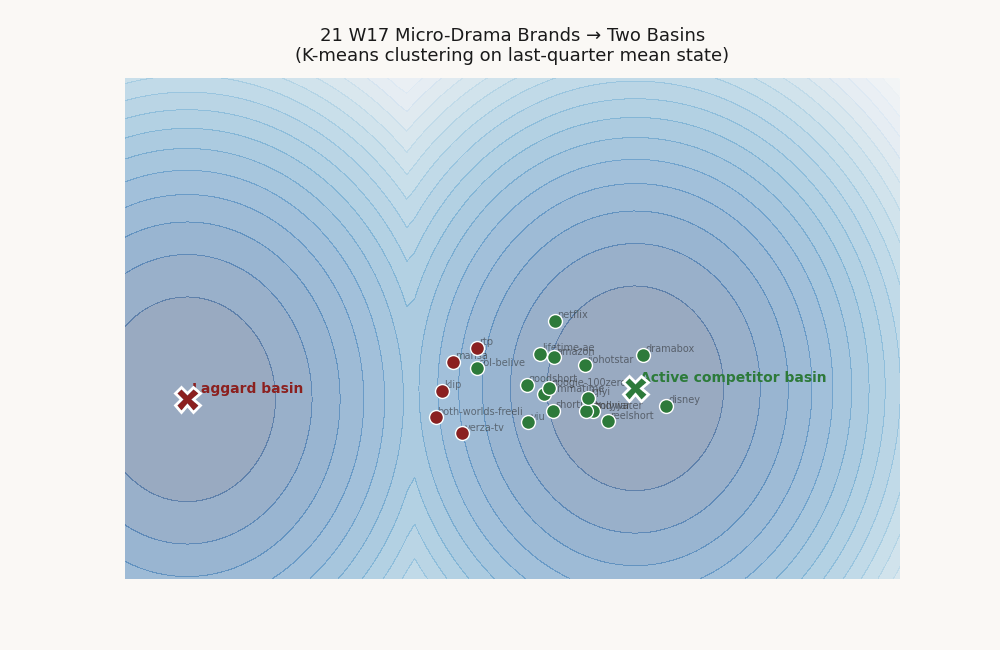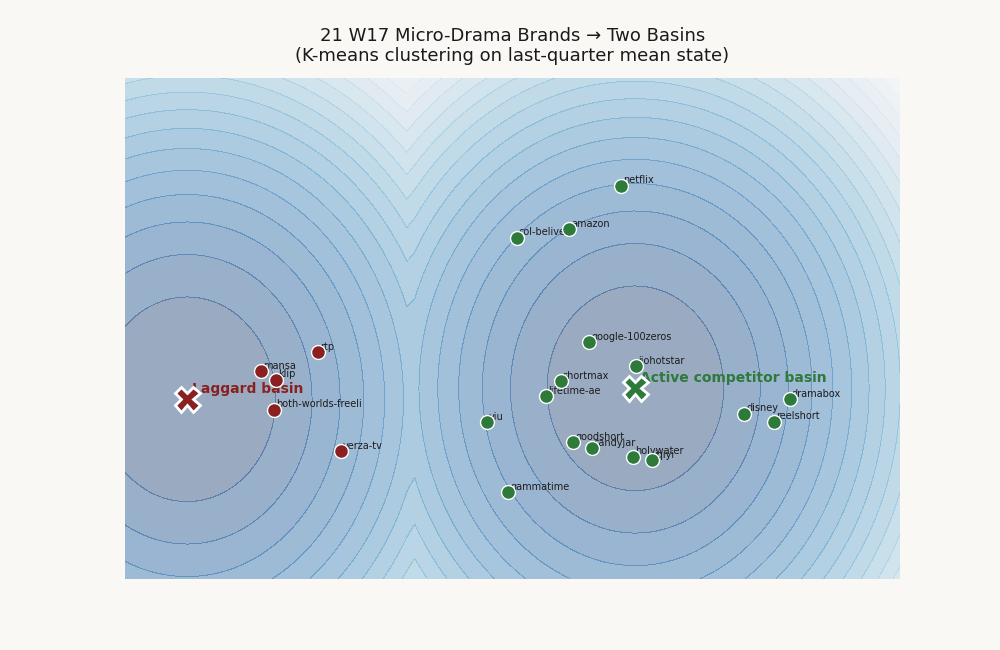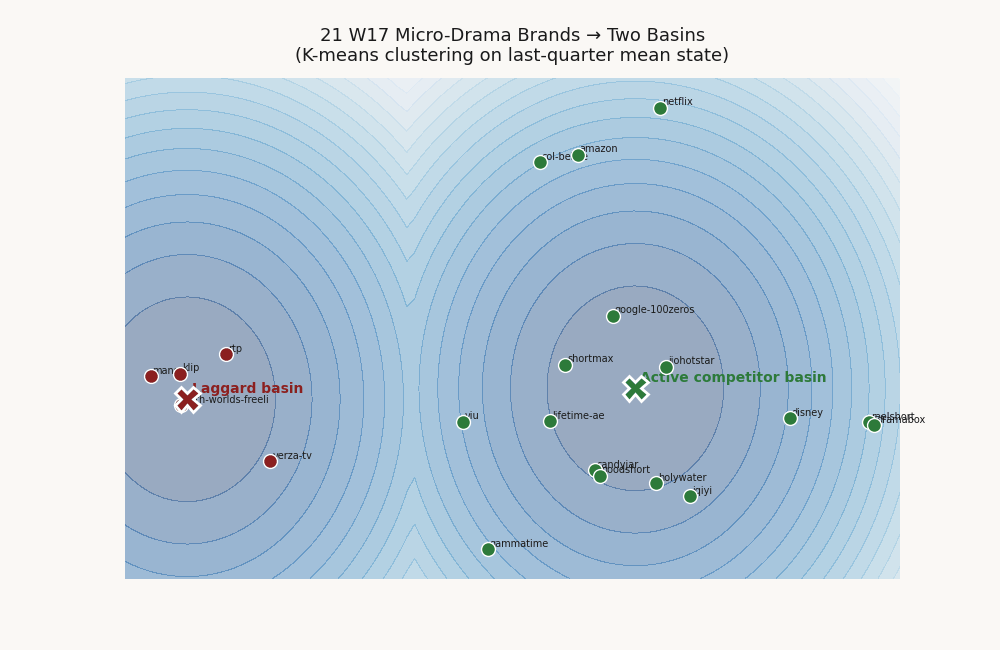
Per-cluster basin geometry
| Cluster | Label | Brands | Validation | Equilibrium x* | Basin radius |
|---|---|---|---|---|---|
| 0 | Active competitor | 16 | 0.895 | [60.8, 59.1, 73.1, 57.0, 66.3] |
3.66 |
| 1 | Laggard | 5 | 1.000 | [27.7, 25.6, 28.5, 24.6, 16.5] |
1.00 |
The laggard cohort is verza-tv, rtp, klip, both-worlds-freeli, mansa. Cluster 1's perfect 1.000 validation reflects a small, tight cohort whose holdout transitions all decay; basin radius is correspondingly narrow. Cluster 0 is the operational basin for the rest of the panel.
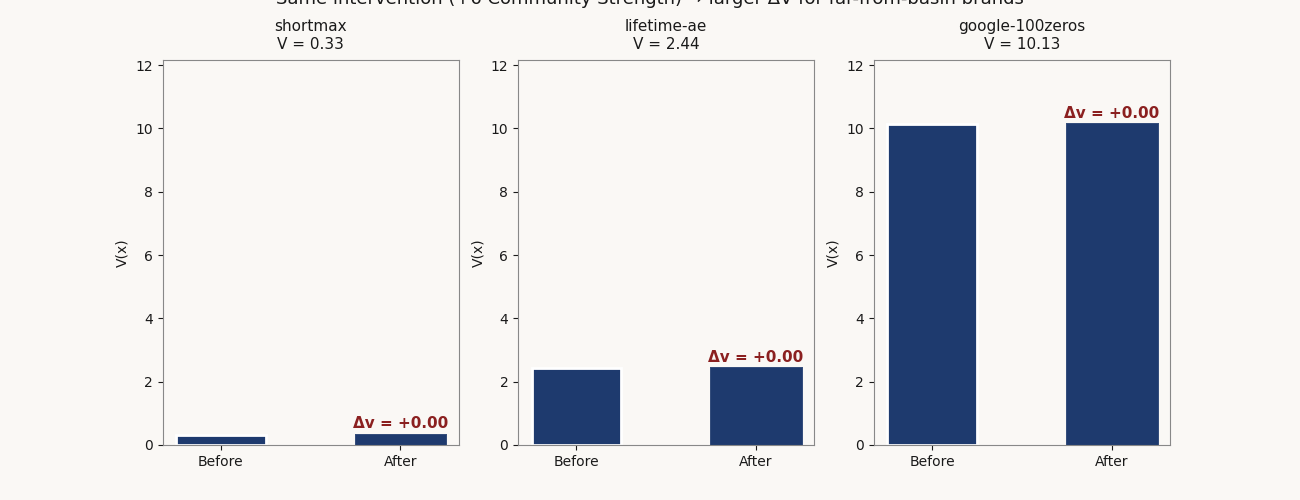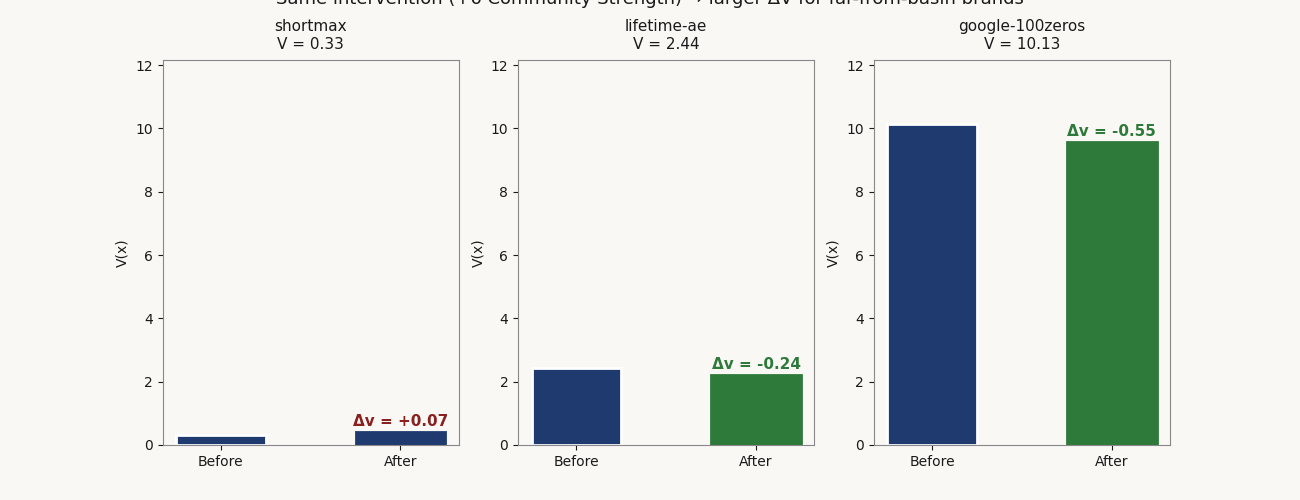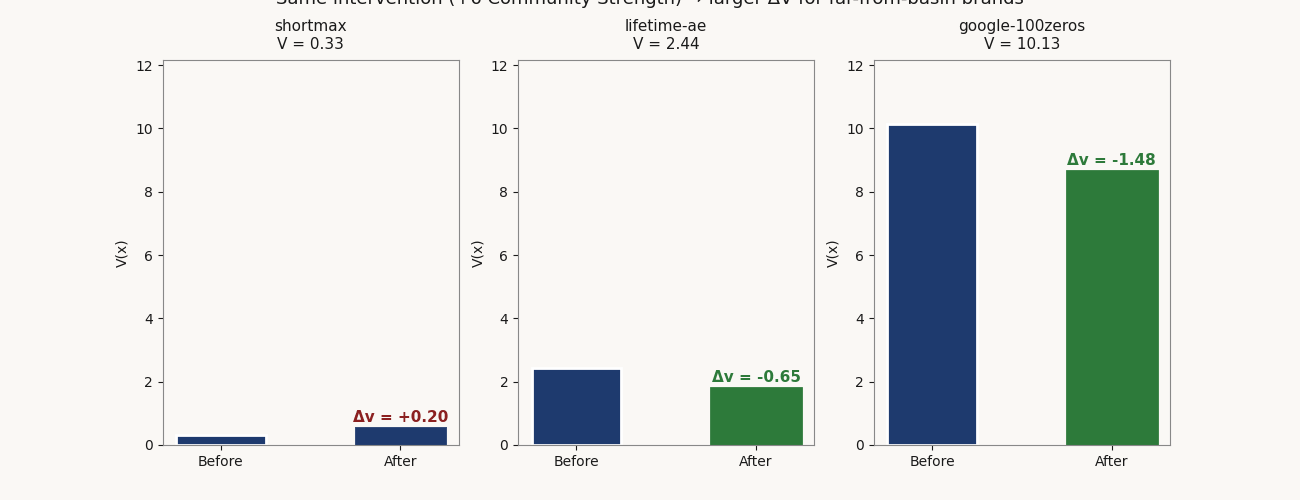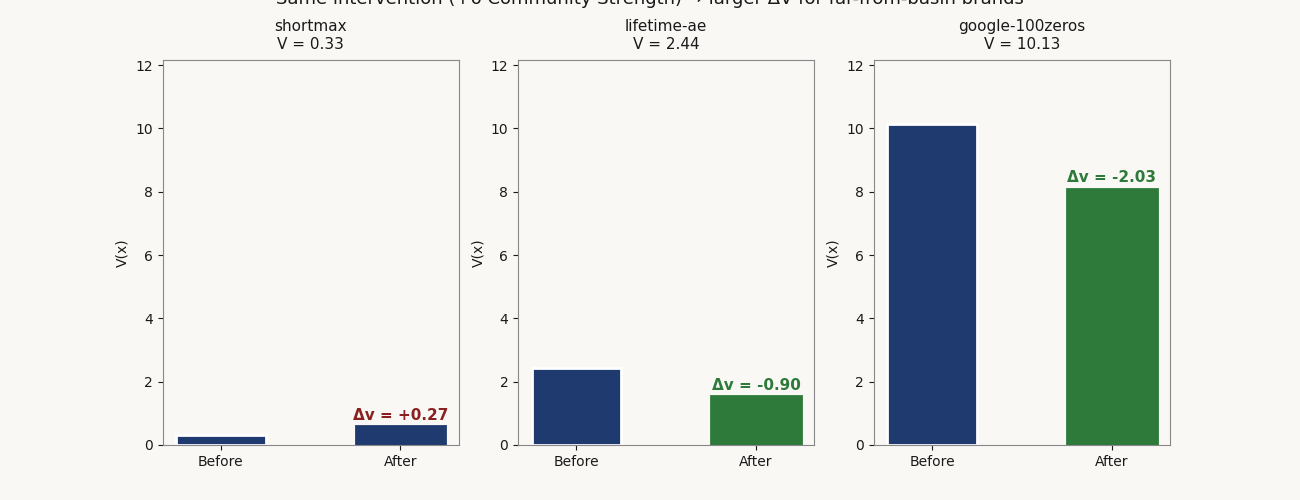
Capital-efficient interventions, three sample brands
specs/interventions.json| Brand | V | Position | Top intervention | ΔV | Cost ($M) | Capital efficiency |
|---|---|---|---|---|---|---|
| shortmax | 0.33 | Near equilibrium | Lean brand refresh | −0.081 | 0.35 | 0.233 |
| lifetime-ae | 2.44 | Marginal | Community / fandom program | −0.896 | 1.20 | 0.747 |
| google-100zeros | 10.13 | Far from basin | Community / fandom program | −2.033 | 1.20 | 1.694 |
Same intervention category at the same cost — community / fandom program at $1.20M — produces 7× the per-dollar V reduction on the far-from-basin brand vs. the marginal one. The V gradient is doing the work: brands far from x* have steeper local slopes, so a fixed Δx maps to a larger ΔV.
ISS / disturbance recovery
For the accepted micro-drama V, random-direction shocks of magnitude ‖dx‖ ∈ {2, 5, 10} were injected at random periods and forward-simulated. Recovery is defined relative to pre-shock V, so transient noise is excluded. Median recovery for all three magnitudes was zero periods; max recovery was 1, 2, and 3 periods respectively. The basin is robust to small and medium shocks; even large shocks recover in ≤ 3 periods under modest mean-reversion stiffness. Comparator readings on chaotic / bistable industries use a fallback V whose absolute scale is not comparable, so they are presented as relative-shape signals only.
Composite vs. Lyapunov-adjusted ranking, with rank deltas and stability class.
Adjusted composite is the brand's composite minus a small penalty proportional to its V reading. Brands inside their basin are unaffected; brands outside their basin are demoted. Three rank flips are non-trivial: ReelShort ↑1, Netflix ↓2, Google/100Zeros ↓4.
| Rank | Brand | Cluster | Composite | Adjusted | V | Stability | In basin? | Δ rank |
|---|
Basin radius for the single-V fit is 4.41. In basin compares V to that radius. Stability class combines V vs. radius with V̇ estimate and distance to x*. Cluster 0 is the active-competitor basin (16 brands, equilibrium ~[61, 59, 73, 57, 66]); cluster 1 is the laggard basin (5 brands, equilibrium ~[28, 26, 28, 25, 16]).
Stability distribution
How V is fit, validated, and translated into a stack-ranking adjustment.
Compact reference for the regulatory-grade reader. All artifacts (joblib pickles, JSON outputs, parquet panels) are preserved in out/; the runner is scripts/run_experiments.py.
Pipeline at a glance
Real W10–W17 micro-drama panel: 21 brands × 8 weeks × 5 dimensions. Stored as parquet at out/panel.parquet. Synthetic comparator panels generated by synth_panel.py for chaotic and bistable regimes.
Quadratic SDP → SOS polynomial lift → neural Lyapunov, in order. Each fit produces a candidate V, an estimated equilibrium x*, and a basin radius (largest c for which decay holds on the training set). Quadratic accepted on real micro-drama at 0.714.
K-means on last-quarter mean position partitions the panel; one quadratic V is fit per cluster. Best-cluster decay fraction routes each holdout transition to its lowest-V cluster — proxy for combined-basin coverage.
Random-direction shock injection (magnitude 2, 5, 10) at random periods, forward-simulated under mean-reversion stiffness 0.10. Recovery time = periods until V drops back below pre-shock level. 105–400 probes per industry per magnitude.
Ten archetypal interventions in specs/interventions.json, each with delta_x vector and dollar cost. For a given brand state x: capital_efficiency(u) = −[V(x+Δx) − V(x)] / cost_M. Ranked per brand.
Adjusted composite = composite − penalty proportional to V. Penalty is small inside the basin, larger outside. Drives the W17 rank deltas: ReelShort +1, Netflix −2, Google/100Zeros −4.
Acceptance threshold & max Lyapunov exponent
A V fit is accepted when validation score ≥ 0.65. Below 0.65 is reported as “no stable V found” — itself a substantive finding, not a failure. The pipeline also estimates the max Lyapunov exponent (MLE) via Rosenstein nearest-neighbor divergence as a cross-check. MLE < 0 indicates trajectory convergence; MLE > 0 indicates chaos. On real micro-drama, the MLE estimate was 3.28 — positive, indicating local stretching, but the V fit still validates because the basin-recovery dynamic dominates the small-scale stretching at the panel timescale. Two independent readings of stability, neither dispositive on its own, both worth reporting.
Honest limitations
• The fitted V is empirical, not formally proven. Real SOS verification requires polynomial dynamics, which the panel does not have. The candidate V is a learned object that satisfies decay on observed trajectories — useful, not bulletproof.
• Industry parameters θ_I are treated as fixed during the fit. Industries evolve. The pipeline must re-fit periodically (the operational target is a nightly run joined to the existing Optuna pipeline).
• Causality is implicit. A brand inside the basin is associated with future stability, but the V framework alone does not prove that interventions reliably move brands inside the basin. CLF-based recommendations need separate causal validation.
• Dimensionality is currently five. If the dimension count grows past fifteen, the SDP becomes expensive and the SOS lift explodes. Plan for PCA on the score space before scaling.
• Bistable / multi-modal industries need cluster-aware fitting. A single quadratic V cannot capture two basins. Per-cluster fit handles this on micro-drama; future verticals may need k > 2.
Recommended next steps
1. Promote per-cluster Lyapunov to default for the micro-drama vertical. Bimodality is structural, not noise. Single-V fits will under-report basin geometry going forward.
2. Wire V into the weekly publish. Append per-brand V, basin membership, and stability classification to each weekly snapshot. One-screen schema addition; gives clients a structural-fragility reading alongside the composite.
3. Build a control-Lyapunov-function (CLF) layer. Capital efficiency currently scores discrete interventions against a fixed Δx. A CLF layer would optimize Δx against a budget constraint (LP or QP, not combinatorial). Better recommendations.
4. Replace mean-reversion ISS forward model with a fitted dynamics model. The current probe uses generic 0.10 stiffness; fitting f(x) per industry from the panel would produce industry-specific recovery curves and let ISS distinguish soft vs. brittle stability.
5. Optuna joint objective. Stability-aware signal-weighting is the natural next move: maximize V-validation × composite predictive accuracy in a single Optuna search.